Noticias
Cómo utilizar herramientas de IA generativa en Obsidian

NVIDIA ha publicado un interesante artículo donde explica cómo podemos utilizar IA generativa en Obsidian. Cuando hablamos del soporte de este tipo de IA los plug-ins ofrecen un gran valor, ya que facilitan la integración y la experiencia de uso con LLMs, siglas en inglés de grandes modelos de lenguaje, que como sabrán muchos de nuestros lectores son la base de la IA generativa.
Las tarjetas gráficas NVIDIA RTX y GeForce RTX cuentan con hardware especializado para acelerar IA, y esto también marca una gran diferencia a la hora de integrar y ejecutar LLMs en local. Dependiendo de la cantidad de memoria gráfica disponible podremos acceder a LLMs con distinta cantidad de parámetros, y más parámetros se traducirán en una mayor precisión y calidad en los resultados obtenidos con la IA generativa.
El gigante verde no se ha olvidado de la importancia del software y de las librerías para acelerar e integrar este tipo de IA, y ofrece un ecosistema muy completo a los desarrolladores que gira alrededor de pilares como TensorRT. Al final, software y hardware se dan la mano para crear uno de los mejores ecosistemas que existen actualmente en el sector.
La integración de herramientas de IA generativa en Obsidian es sencilla porque esta aplicación soporta complementos desarrollados por la comunidad, lo que supone un gran valor funcional. Entre los plug-ins soportados hay varios que permiten a los usuarios conectar Obsidian a un servidor de inferencia local como Ollama o LM Studio.
Para conectar Obsidian a LM Studio solo es necesario habilitar la funcionalidad del servidor local en LM Studio y seguir estos pasos:
- Hacer clic en el icono “Desarrollador que está situado en el panel izquierdo.
- Cargar cualquier modelo que tengamos descargado.
- Habilitar el interruptor CORS y por último hacer clic en “Iniciar”.
- Guardar la URL que nos aparecerá al final, ya que necesitaremos esta información para conectar.
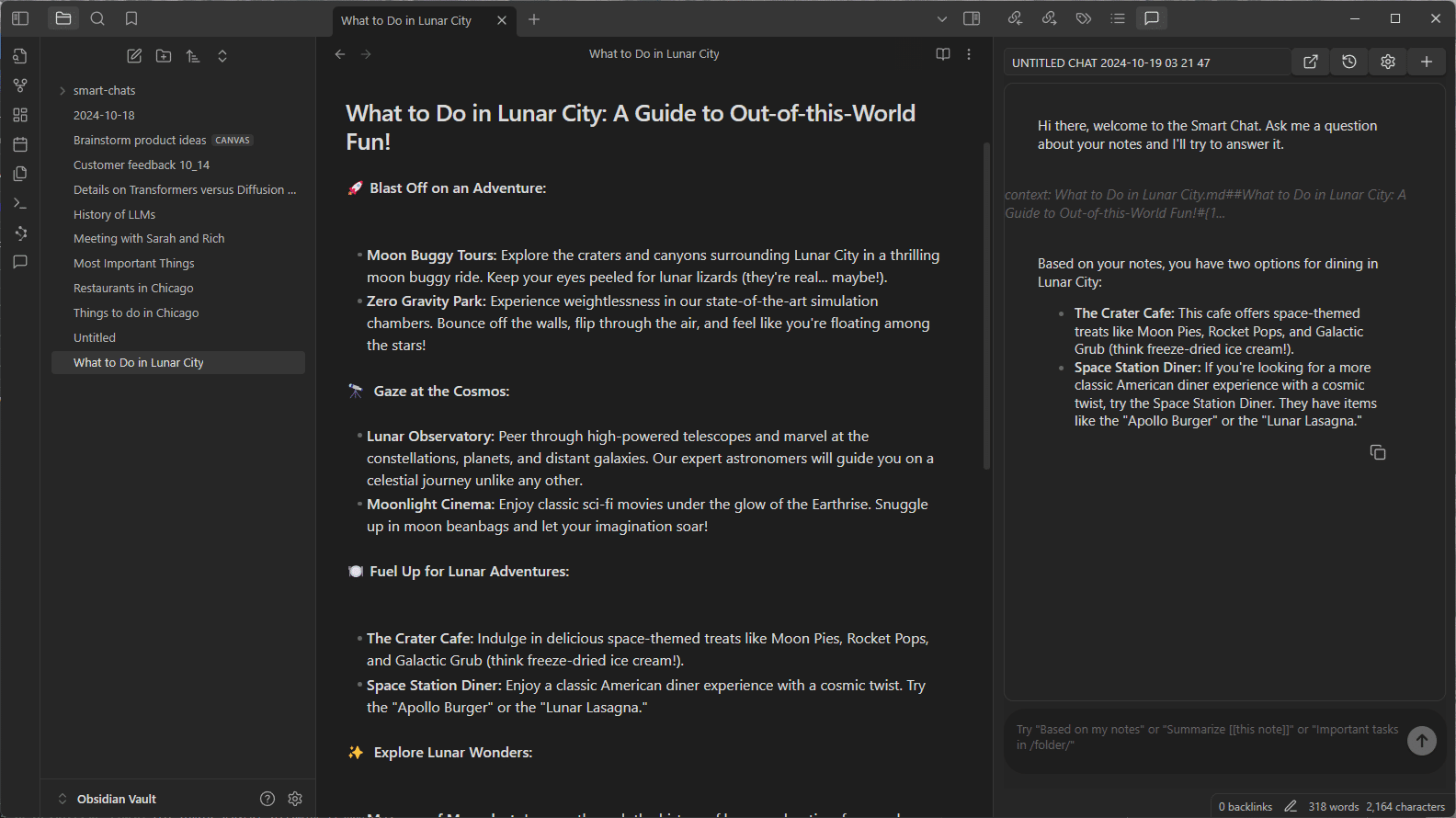
A continuación ejecutamos Obsidian y abrimos el panel “Configuración”. Hacemos clic en “Complementos de la comunidad” y luego en “Explorar”. Hay varios complementos de la comunidad relacionados con los LLM, pero las dos opciones más populares y más utilizadas son el generador de texto y las conexiones inteligentes.
El primero es muy útil para generar contenido en una bóveda de Obsidian, como notas y resúmenes sobre un tema de investigación. El segundo es una buena opción para hacer preguntas sobre el contenido de una bóveda de Obsidian, como la respuesta a una pregunta poco conocida guardada hace tiempo. Cada complemento tiene su propia forma de ingresar la URL del servidor LM:
- Para el generador de texto nos vamos a configuración y seleccionamos “Personalizado” y “Perfil del proveedor”, y pegamos la URL guardada previamente en “Punto final”.
- Para las conexiones inteligentes tenemos que configurar los ajustes después de iniciar el complemento. En el panel de configuración del lado derecho de la interfaz entramos en “Personalizado local (formato OpenAI)” para la plataforma del modelo. Ahora introducimos la URL previamente guardada y el nombre del modelo (por ejemplo, “gemma-2-27b-instruct”) en sus respectivos campos, tal como aparecen en LM Studio.
Una vez que se completen los campos indicados todos los complementos funcionarán. La interfaz de usuario de LM Studio también mostrará la actividad registrada, lo que nos permitirá ver en tiempo real qué es lo que sucede en el servidor local.
Imagen de portada generada con IA.













HPE actualiza Greenlake con mejoras para simplificar la gestión de entornos híbridos

Bluesky se consolida como alternativa a X superando los 20 millones de usuarios

Riverbed mejora la experiencia móvil de los empleados con Aternity Mobile

Microsoft presenta el Mini-PC para la nube, Windows 365 Link

Europa marcará una cifra récord de inversión en TI en 2025

La evolución de las arquitecturas de redes hacia las SDN

Salesforce lidera la tercera ola de la IA con Agentforce

Inteligencia artificial, agilidad y desarrollo de aplicaciones seguras

“En el futuro, todas las empresas serán organizaciones con inteligencia artificial”

“Los datos son la base para transformar cualquier organización”

Microsoft acusa a Google de «operaciones encubiertas» para influir en la regulación cloud en la UE

Responder al riesgo con IA y Machine Learning
HPE actualiza Greenlake con mejoras para simplificar la gestión de entornos híbridos

Granite 3.0, la nueva generación de modelos de Inteligencia Artificial para empresas de IBM
“En el futuro, todas las empresas serán organizaciones con inteligencia artificial”

Sophos compra Secureworks para avanzar en ciberseguridad empresarial

Microsoft dejará crear agentes de IA personalizados con Copilot Studio e incorpora diez a Dynamics 365

Pure Storage nombrada Líder en el Cuadrante Mágico de Gartner para plataformas de almacenamiento de archivos y objetos
-

 OpiniónHace 6 días
OpiniónHace 6 díasLa nube resiliente: arquitecturas multirregión en Microsoft Azure
-

 NoticiasHace 6 días
NoticiasHace 6 díasEl poder del NAS: una guía para iniciarse en el almacenamiento inteligente
-

 OpiniónHace 5 días
OpiniónHace 5 días10 predicciones para los proveedores de servicios gestionados en 2025
-

 NoticiasHace 5 días
NoticiasHace 5 díasLa Comisión Europea multa a Meta con 798 millones por perjudicar a la competencia de Marketplace