Noticias
Glosario de los seis términos básicos del Machine Learning

Una de las tecnologías llamadas a revolucionar el panorama TIC más inmediato es el Machine Learning. A medio camino entre la analítica y la Inteligencia Artificial, la inversión en estas herramientas en los próximos tres años será casi el doble que la actual, según el estudio Global CIO Point of View de IDC, donde se predice que, para 2020, el 64% de las empresas habrán adoptado esta tecnología, a nivel mundial.
En cuanto a los sectores que más se beneficiarán de esta tecnología, según datos de la española Tinámica, serán las empresas industriales (sobre todo la del automóvil), las compañías del retail y la energía y, por último, el sector bancario.
En el desarrollo del Machine Learning son necesarias habilidades muy concretas y muy nuevas como ser expertos en el análisis de datos, tener un perfil matemático, capacidad de comunicación, estar en continuo aprendizaje y tener un perfil heterogéneo que aglutine todas las capacidades anteriores, ya que aún no existe uno definido como «experto en Machine Learning».
Como son muchos los profesionales que, al final, intervienen en el desarrollo y uso de esta tecnología, es importante para ellos tener un lenguaje común para investigar, acelerar las pruebas, mejorar la precisión de las respuestas y tomar mejores decisiones. Debido a que el análisis de datos tiene sus raíces en la estadística y la informática, está repleto de terminología especializada, pero pocos son los glosarios que la reúnan toda. Aquí recopilamos los seis conceptos más básicos:
Machine Learning
Como ya comentábamos en un artículo anterior, este concepto puede confundirse con el de Inteligencia Artificial. «El ML es un paso previo a la Inteligencia Artificial (IA) para que ésta se desarrolle en su totalidad. Concretamente, es un aprendizaje de máquinas que utilizan muchos datos con el objetivo de ser cada vez más inteligentes a la hora de hacer cosas. El ML se alimenta de algoritmo e información, es algo así como llevar la inteligencia al dato».
«El ML está muy unido a la analítica porque ésta es la que le dice a la máquina que cierto comportamiento es adecuado o no. Por ejemplo, en una tienda quieren saber si una prenda es interesante para el consumidor o no, a base de que le llegue muchísimas veces la información de que ‘no interesa´, la máquina va aprendiendo que esa prenda no gusta porque nadie la está comprando».
Algoritmos
Un algoritmo es una serie de pasos matemáticos u operacionales específicas para resolver un problema o realizar una tarea. En el contexto del Machine Learning, un algoritmo transforma o analiza datos para llevar a cabo las siguientes tareas:
- Análisis de regresión.
- Clasificar a los clientes.
- Encontrar relaciones entre los SKU (códigos compuestos por letras y números que identifican las características de un producto).
Modelo
La definición más simple de un modelo es la representación matemática de las relaciones en un conjunto de datos. O lo que es lo mismo, es una forma simplificada y matemáticamente formalizada de aproximarse a la realidad y hacer predicciones a partir de esta aproximación. Un ejemplo simple que encontramos en el huffingtonpost es el siguiente:
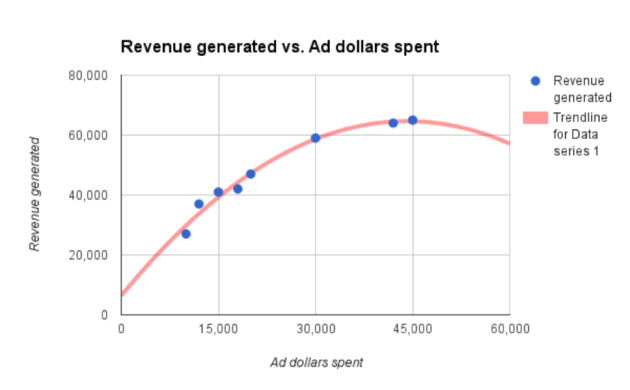 Fuente: huffingtonpost
Fuente: huffingtonpost Los puntos azules son los inputs (por ejemplo, los datos) y la línea roja representa el modelo. Hay dos cosas claves para entender estos modelos:
1 – Pueden complicarse. El que aparece aquí es simple porque los datos son simples, si los datos son más complejos, evidentemente, el modelo predictivo se puede complicar y no sería retratado en un gráfico de solo dos ejes. Un ejemplo de modelo complejo sería el reconocimiento de voz que utiliza Siri que es capaz de reconocer el significado de los sonidos.
2 – Los modelos no son mágicos, pueden ser inexactos o simples por muchas razones. Volviendo al ejemplo anterior, se podría pensar que el autor eligió el algoritmo incorrecto para generar ese modelo, ya que la línea roja se inclina en un momento dado y, como ese modelo predice un ingreso adicional podría parecer algo contradictorio que esta fuera descendente. Esto debería llamar la atención de los equipos de marketing y ciencia de datos.
Un algoritmo diferente podría generar un modelo que predijera la disminución de los rendimientos incrementales, que no es lo mismo que decir menores ingresos.
Características/ variables
Objetivamente, las características son elementos o dimensiones de un conjunto de datos; por lo tanto, elegir las informativas, discriminatorias e independientes es un paso crucial para lograr algoritmos efectivos.
Por ejemplo, si se están analizando datos para averiguar el comportamiento de un cliente (edad, ubicación, profesiones, compras anteriores, etc.), ¿cuáles de estas características tendrían valor predictivo para el resto de clientes? Probablemente se podría hacer conjeturas inteligentes de muchos de estos datos que ayudarían a establecer comportamientos similares para otro grupo de población.
Supervisión vs no supervisión
El aprendizaje automático puede tener dos enfoques fundamentales. Por una parte, el aprendizaje supervisado, que es una forma de enseñar a un algoritmo cómo hacer su trabajo cuando tiene un conjunto de datos para los que sabe «su respuesta». Por ejemplo, para crear un modelo que pueda reconocer imágenes de datos a través de este proceso, el sistema ya tendría las imágenes etiquetadas como «gato» o «no gato».
En el mundo más empresarial se puede usar este tipo de algoritmo para clasificar a los clientes según seis prototipos, por ejemplo, entrenando al sistema con datos de clientes existentes que ya están categorizados de acuerdo a estos tipos.
Por otra parte, se denomina aprendizaje no supervisado cuando un algoritmo analiza el dato que no ha sido etiquetado con una respuesta para identificar patrones o correlaciones. Este sistema puede analizar un gran conjunto de datos de un cliente y obtener resultados que indiquen que este pertenece a siete grupos grandes o doce pequeños. A continuación, el científico de datos puede analizar estos resultados para averiguar qué define a cada grupo y cómo podría impactar en tu negocio.
En la práctica, la mayoría de los modelos se construyen usando una combinación de ambos.
Deep Learning
El Deep Learning es un tipo de aprendizaje automático, utiliza múltiples capas de cálculo y otras más avanzadas con características abstractas y de alto nivel. En el ejemplo que mencionábamos antes de las fotos de gato, la primera capa podría referirse a un conjunto de líneas que pudieran crear una figura, y las capas posteriores pudieran buscar elementos más concretos, como ojos o una cara completa.
Normalmente se usa esta herramienta en problemas muy grandes y complejos como los que hay en los motores de recomendación de Netflix o Amazon.
Cómo aplicar estos términos a una campaña de marketing
Para aplicar todos estos conceptos en un ejemplo práctico y entendible, hemos hablado con Antonio Vidal, premio Mejor Científico de Datos en España 2017 y Data Science Manager de SIVSA, quien nos ha explicado cómo se aplicaría el Machine Learning a una campaña sencilla de marketing.
El objetivo: predecir cuántos clientes van a aceptar nuestra oferta de un producto.
Pasos a seguir:
- Sacar datos de los clientes y de campañas anteriores parecidas y del mismo producto.
- Generar las variables necesarias para entender el algoritmo y, en base a esto, producir el modelo.
- Validar el modelo con datos de prueba para ver si funciona bien (estimación de resultados).
- Obtienes una probabilidad de qué clientes van a aceptar tu oferta.
- Le envías la oferta a los clientes con mayor probabilidad de éxito.













Microsoft Ignite 2024: más versatilidad para la IA, mejoras en Teams y aumento de la seguridad

«Los agentes autónomos de Salesforce nos ayudan a hacer mejor nuestro trabajo»

IBM sigue avanzando en la corrección de errores en sistemas cuánticos

«En un futuro podremos saber desde el primer momento si estamos siendo atacados»

NVIDIA y Microsoft potencian el desarrollo con IA en PCs con RTX

Soberanía de datos: hacia la privacidad total en la mensajería instantánea empresarial

Salesforce lidera la tercera ola de la IA con Agentforce

Inteligencia artificial, agilidad y desarrollo de aplicaciones seguras

“Los datos son la base para transformar cualquier organización”

Microsoft acusa a Google de «operaciones encubiertas» para influir en la regulación cloud en la UE

Responder al riesgo con IA y Machine Learning

Salesforce Agentforce World Tour Madrid 2024: donde la innovación te espera
Microsoft Ignite 2024: más versatilidad para la IA, mejoras en Teams y aumento de la seguridad

Pure Storage nombrada Líder en el Cuadrante Mágico de Gartner para plataformas de almacenamiento de archivos y objetos

Arm y Qualcomm van a la guerra

Penguin Random House cambia su copyright para proteger de la IA a los autores

Arquitecturas multiagente: la colaboración entre agentes de IA, más cerca

¡No te pierdas nada! ¡Sigue aquí el streaming del eFactura Fórum II!
-

 OpiniónHace 6 días
OpiniónHace 6 días10 predicciones para los proveedores de servicios gestionados en 2025
-

 NoticiasHace 6 días
NoticiasHace 6 díasAMD despedirá al 4% de su plantilla mientras se centra en IA y centros de datos
-

 NoticiasHace 2 días
NoticiasHace 2 díasEl Capitan es el nuevo superordenador más potente y rápido del mundo
-

 NoticiasHace 6 días
NoticiasHace 6 díasLa Comisión Europea multa a Meta con 798 millones por perjudicar a la competencia de Marketplace